参考:AWS Glue + S3 + csv ファイルでデータレイク
Apache Spark エンジンで ETL を行う。Python3(PySPARK)
Glue データカタログはメタデータレポジトリであり、実態データは持たない。実態データはS3やDBなどを参照している。
Glueから重複データの削除などはできない模様。またETLで重複削除のコンポーネントがあるが、既存のS3上のPerquetなどのデータは削除できなかった。
Perquet ごとにデータを持つ。Perquetの合計が実態データとなる。
(1)
Custom Transform 内では Python などでコーディングが可能。しかし debug が困難。debug は print 文で行う。
結果はS3に自動でアップロードされる。ジョブの結果の"Run Details" の "Outputlogs" に print 文の結果が出力される。事前設定不要。
例:
print ("test")
print ("Col1" , col(Col1))
(2)Visual ETLでのデータのプレビューによるdebug
Visual ETL のコンポーネントではデータとスキーマをチェックすることが可能。
Preview はデフォルトは100レコード。1000レコードまで増やすことが可能。join などデータが増える場合にdebugが役に立つ。
しかし 1000だと outputが大きすぎて "Output size extended xxxxxx bytes" エラーとなる。
(1)注意事項
・データカタログでスキーマを決めた後、その後パーティションキーを設定するとなぜかカラムの順番変更されてう。
S3のCSVからデータを読み込む場合はカラムの順番で読み込むので読み込み失敗する。
・データカタログのスキーマでパーティションキーを設定した場合、Visual ETL でパーティションキー名が col5 , col6 , col7 とかに認識されてしまった。原因不明。
・Visual ETL でコンポーネントの順番を変更すると、左右の位置も変わったりして join が left , right で変ったりしたりするので注意が必要。
またコンポーネントの名前を変更すると順番が変って join の順番が変ったりするので同じく注意が必要。
・Visual ETL の "script"タブで全体のスクリプトを通して確認が可能。ここでキーワード検索などが便利。ただし ("locked")と表示されているとおり編集はできなさそう。
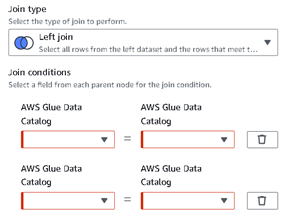
・テーブルの left join で複数キーのjoinは condition を2個以上設定して対応する。
(*)おそらくテーブルを Left join などする場合は、事前にテーブルのスキーマでカラムの追加が必要。
・テーブルをコピーしたい場合は、スキーマを Json 形式でコピー、ペーストして作成する。
・データベースはS3にアップロードして、csvのカラムとデータベースのスキーマ名を合わせるだけで自動でロードされる。
・"Error parsing a column in the table.Table can not convert value of type string to a long value"のエラーの対処
テーブルのスキーマと実データの方が一致していない。どちらかを見直す。テーブルのスキーマの型は後からそれだけ変更可能。
・S3上のcsv ファイルをデータベースとして取り込むとき、1行目が取り込まれてしまい、"タイプミスパッチ"エラーとなる。
テーブルのプロパティで "skip header line count "で 1 を設定する。
これでS3上の csv で 1行目のヘッダーは無視される。
・【BUG】2024/8
Glue の Visual ETLでデータベースと"Custome Transform" の間の連結で失敗する。
→原因不明。一度他のデータベースを選択して元に戻したら復活した。
・CustomeTransformは "DynamicFrameCollection" 型を返す。これは処理によってはDynamicFrameを分割する場合もあるため、Collection型となる。
例:
return DynamicFrameCollection({"above_30": filtered_dynamic_frame, "below_30": below_30_dynamic_frame}, glueContext)
続く処理ではSelectFromCollectionで取り出す必要あり。
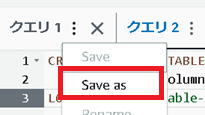
・Athenaで Query save の方法が分からない。
→分かりにくい場所にある。次の部分で保存可能。
・Glue は QuicksightやAthenaと連携が可能。Glue で加工したデータ(data lake)を Athena での分析や QuckSightでの可視化が可能。
・日付の指定はクォートでlくくる。例: '2024/01/01'
[トップへ]