Bedrock が AWS のメインのAIサービス。この中で言語モデルを選択することが可能。
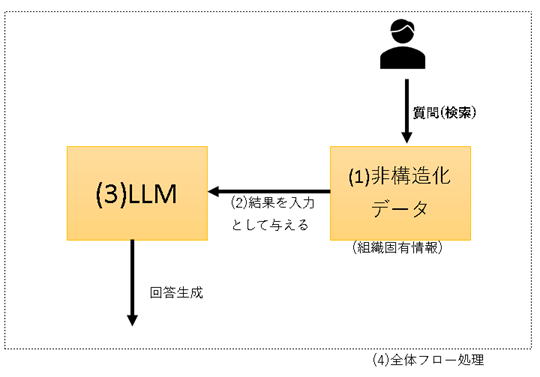
「RAG(検索拡張生成)」とは自然言語処理における手法の一つです。検索エンジンと生成モデルを組み合わせて質問に対する回答を生成します。具体的には、与えられた質問に対して関連する文書を検索し、その情報をもとに回答を生成する技術です。このアプローチにより、より正確かつ詳細な回答生成が可能になります。
検索方法が重要となります。
(2024年3月現在、今後サポート範囲拡大など改善していくと思われる)
| 1.Kendra + Bedrock | 2.Bedrock + ベクトル DB | 3.Agents for Amazon Bedrock | 4.ナレッジベース for Amazon Bedrock | |
| (1)データ保存場所 | Kendra | 色々 | S3 | S3 |
| (2)検索方法 | Kendraによる | ベクトル検索 ユーザ実装 |
OpenSearch Serverless (セマンティック検索システムとテキスト検索システムに 2 つの検索クエリを実行し、インテリジェントなランキングによって結果を組み合わせることで機能) OpenSource |
|
| (3)基礎モデル | ユーザ実装 anthropic.claude-v2:1など |
ユーザ実装 | Amazon Titan Embeddings | |
| (4)フロー処理 | ユーザ実装 Langchainなど |
ユーザ実装 | ||
| (5)ナレッジ更新 | Kendra | ユーザ実装 | ||
| (6)日本リージョン | 〇 | 〇 | × (2024年4月現在で日本リージョンでは未対応) | × (2024年4月現在で日本リージョンでは未対応) |
| 備考 | ・Bedrock -> エージェントで作成。日本リージョンでは表示されないが、バージニア北部などでは表示される。 ・複数のLambda関数を自然言語で操作 ・モデルの知らない情報、最新の情報にアクセス ・数クリックでタスク作成 ・LangChainでもおなじようなことができる。 ・エージェントを作成。Lamdaなど 自然言語での指示も可能 ・アクショングループ、ナレッジベース、詳細プロンプトの設定などが可能。 ・前処理を挟むことが可能。 ・本日のニュース、指定したブログなど不足情報を保続しながら回答生成が可能。 |
・Bedrock -> ナレッジベース で作成。日本リージョンでは表示されないが、バージニア北部などでは表示される。 "Amazon BedrockのKnowledge base "とはRAGを GUI で簡単に作成。 ・Vector Store ・データソース |
Amazon Bedrock ナレッジベーの開発メモはこちら
Amazon Bedrock エージェントの開発メモはこちら
LangChainは、言語理解や生成を行うアプリケーションの構築をサポートするツールキットです。検索拡張生成(RAG)やプロンプトエンジニアリングなどの言語タスクを連鎖させることができます。
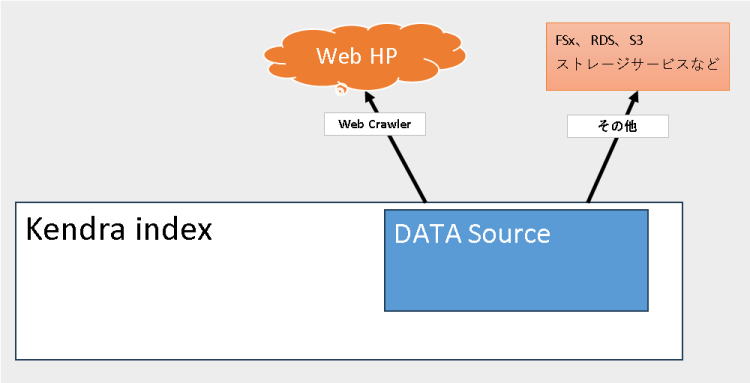
ドキュメントを S3 にアップロードする。S3へは wget などで取得した html や pdf などでも可能。モデルは Titan Embeddings G1 - Textv1.2 などから選択。
RAGとして GUI で chat が可能。
1.Kendra 検索エンジンと連携
(*)Kendra は起動しているだけで課金、高額なので注意
(1)
Kendra は優秀な crawer 。インデクスを作成して全文検索としてQ&Aを行う。結果の数件をBedrock RAG にchain して生成AIにより回答を取得する。
(2)Q&Aを実施し、回答の結果数件から LLM で 文書を生成する。
python3.8 sample.py "入会方法を教えてください"
sample.py
| import os import boto3 import sys from langchain_community.llms import Bedrock from langchain.chains import RetrievalQA from langchain_community.retrievers import AmazonKendraRetriever from langchain.prompts import PromptTemplate os.environ['AWS_CONFIG_FILE'] ="/.aws/config" os.environ['AWS_SHARED_CREDENTIALS_FILE'] = "/.aws/credentials" #自分のkendra の index id を設定 kendra_index_id="********-****-****-****-************" attribute_filter = {"EqualsTo": {"Key": "_language_code","Value": {"StringValue": "ja"}}} #渡す検索結果の件数を変更するには次の20を変更する retriever = AmazonKendraRetriever(index_id=kendra_index_id,attribute_filter=attribute_filter,top_k=20) llm = Bedrock( model_id="anthropic.claude-v2:1", model_kwargs={"max_tokens_to_sample": 1000} ) #テンプレートは Bedrock のサンプルを参考 prompt_template = """ {context} \n\nHuman: 上記参考文書を元に、<question>に対して説明してください。 参考文書に無かった場合は「文書に情報なし」とだけ答えてください。 <question>{question}</question> \n\nAssistant:""" PROMPT = PromptTemplate(template=prompt_template, input_variables=["context", "question"]) chain_type_kwargs = {"prompt": PROMPT} qa = RetrievalQA.from_chain_type(retriever=retriever,llm=llm,chain_type_kwargs=chain_type_kwargs) result = qa.run(sys.argv[1]) print(result) |
参考:Amazon Bedrock テキストモデルのプロンプトテンプレートと例
https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/prompt-templates-and-examples.html
(*1)RAGとしてデータソースに存在しない場合も基礎モデルから回答してしまうので「参考文書に無かった場合は「文書に情報なし」とだけ答えてください。」が必要。
(*2)「kendraの参考文献のURLを教えてください」という追加すると、存在しない適当なURLを回答してくる。」
(*3)文書の長さを指定しないと短く回答する。「300文字」とか条件を付けると長く回答してくれる。